Tag: replication
-
Update on the Replication Bayes Factor
In December I already blogged about the ReplicationBF package, I made available on GitHub. It allows you to calculate Replication Bayes Factors for t- and F-tests. The preprint detailing the formulas for the latter was outdated and the method in the package was not optimal, so I recently updated both.
-
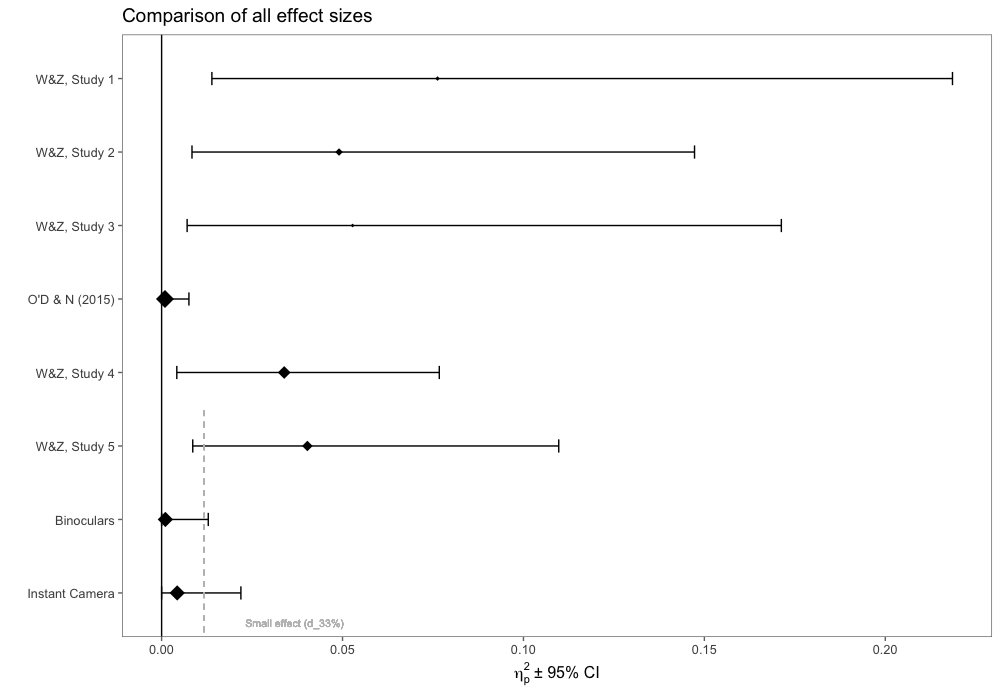
New Preprint: Does it Actually Feel Right?
In a recent post, I mentioned a replication study we performed. We have now finalised the manuscript and uploaded it as a pre-print to PsyArXiv. Update (25.04.2018): The paper is now published at Royal Society Open Science and available here.
-
ReplicationBF: An R-Package to calculate Replication Bayes Factors
Some months ago I’ve written a manuscript how to calculate Replication Bayes factors for replication studies involving F-tests as is usually the case for ANOVA-type studies. After a first round of peer review, I have revised the manuscript and updated all the R scripts. I have a written a small R-Package to have all functions…
-
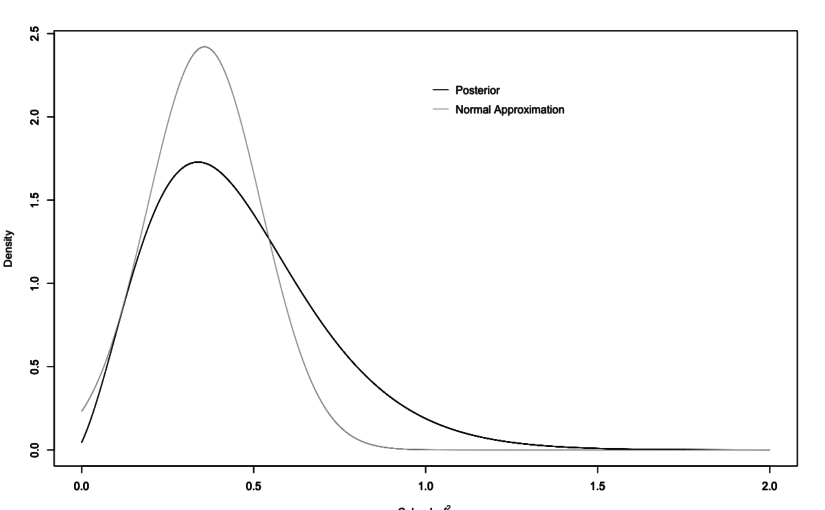
New Preprint: A Bayes Factor for Replications of ANOVA Results
Already some weeks ago I have finished up some thoughts for a Replication Bayes factor for ANOVA contexts, which resulted in a manuscript that is available as pre-print at arXiv. The theoretical foundation was laid out before by Verhagen & Wagenmakers (2014) and my manuscript is mainly an extension of their approach. We have another paper…
-

Research is messy: Two cases of pre-registrations
Pre-registrations are becoming increasingly important for studies in psychological research. This is a much needed change since part of the “replication crisis” has to do with too much flexibility in data analysis and interpretation (p-hacking, HARK’ing and the like). Pre-registering a study with planned sample size and planned analyses allows other researchers to understand what…