Category: Science
-
p-hacking destroys everything (not only p-values)
In the context of problems with replicability in psychology and other empirical fields, statistical significance testing and p-values have received a lot of criticism. And without question: much of the criticism has its merits. There certainly are problems with how significance tests are used and p-values are interpreted.1 However, when we are talking about “p-hacking”,…
-
Introduction to Bayesian Statistics (Slides in German)
Recently, I had the opportunity to give a lecture on Bayesian statistics to a semester of Psychology Master students at the University of Bonn. The slides, which are in German, I’d like to share here for interested readers.
-
ReplicationBF: An R-Package to calculate Replication Bayes Factors
Some months ago I’ve written a manuscript how to calculate Replication Bayes factors for replication studies involving F-tests as is usually the case for ANOVA-type studies. After a first round of peer review, I have revised the manuscript and updated all the R scripts. I have a written a small R-Package to have all functions…
-
Thoughts on the Universality of Psychological Effects
Most discussed and published findings from psychological research claim universality in some way. Especially for cognitive psychology it is the underlying assumption that all human brains work similarly — an assumption not unfounded at all. But also findings from other fields of psychology such as social psychology claim generality across time and place. It is…
-
Critiquing Psychiatric Diagnosis
I came across this great post at the Mind Hacks blog by Vaughan Bell, which is about how we talk about psychiatric diseases, their diagnosis and criticising their nature. Debating the validity of diagnoses is a good thing. In fact, it’s essential we do it. Lots of DSM diagnoses, as I’ve argued before, poorly predict…
-

Stop the “Flipping”
I came across this interesting article at The Thesis Whisperer blog. It starts with the hypothesis being an academic is similar to “running a small, not very profitable business”. This is mainly down to two problems: Problem one: There are a lot of opportunities that could turn into nothing, so it’s best to say yes…
-
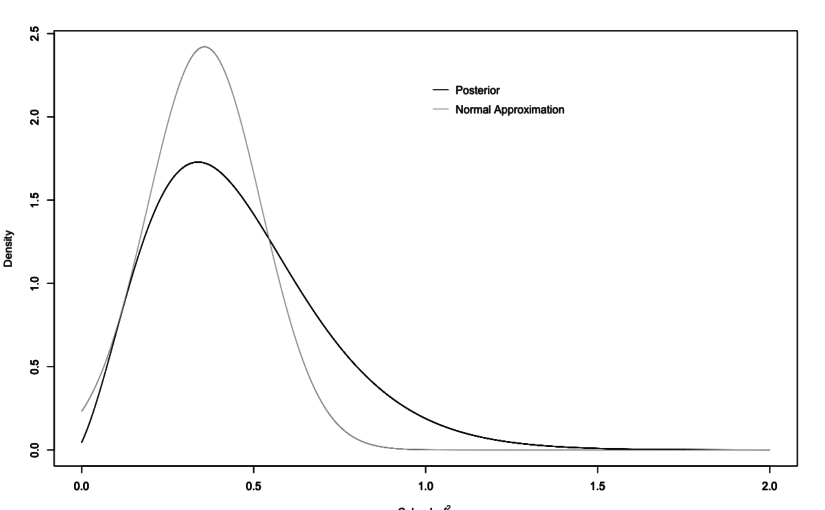
New Preprint: A Bayes Factor for Replications of ANOVA Results
Already some weeks ago I have finished up some thoughts for a Replication Bayes factor for ANOVA contexts, which resulted in a manuscript that is available as pre-print at arXiv. The theoretical foundation was laid out before by Verhagen & Wagenmakers (2014) and my manuscript is mainly an extension of their approach. We have another paper…
-
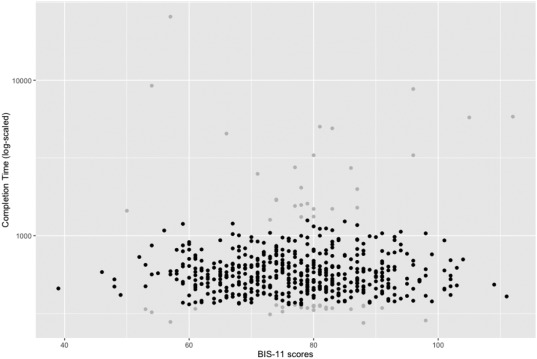
New Paper: Impulsivity and Completion Time in Online Questionnaires
I’ve got my first first-author-paper published in Personality and Individual Differences. The paper is titled “Reliability and completion speed in online questionnaires under consideration of personality” (doi:10.1016/j.paid.2017.02.015) and was written together with Lina and Christian.
-

Research is messy: Two cases of pre-registrations
Pre-registrations are becoming increasingly important for studies in psychological research. This is a much needed change since part of the “replication crisis” has to do with too much flexibility in data analysis and interpretation (p-hacking, HARK’ing and the like). Pre-registering a study with planned sample size and planned analyses allows other researchers to understand what…