In February and March this year, I stayed at the Eindhoven Technical University in the amazing group with Daniël Lakens, Anne Scheel and Peder Isager, who are actively researching questions of replicability in psychological science. Over the two months I have learned a lot, exchanged some great ideas with the three of them – and was able to work together with Daniël on a small overview article.
If we aim to move away from applying significance tests mindlessly, we need proper statistical tools to evaluate “null effects”. With “null effects” we primarily mean non-significant results, as it is common practice to consider these as null results. The problem is, that non-significant results are not directly interpretable: We do not know if the non-significance is due to a lack of power (thus, if it is a Type II error) or if there is truly no effect.1 But there are also other scenarios where we might be primarily interested in the absence of an effect – in these cases, simply looking for non-significance is not adequate.
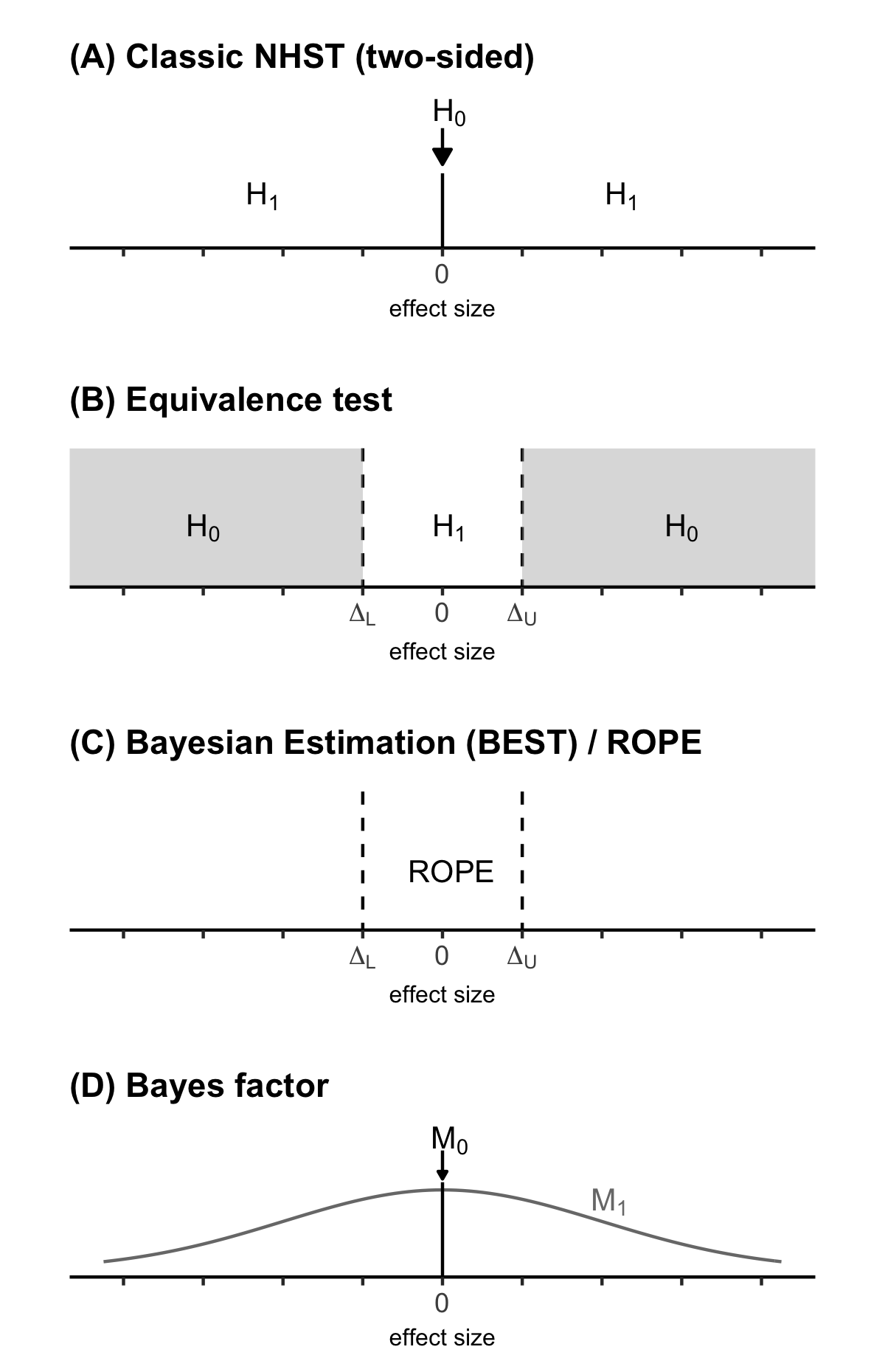
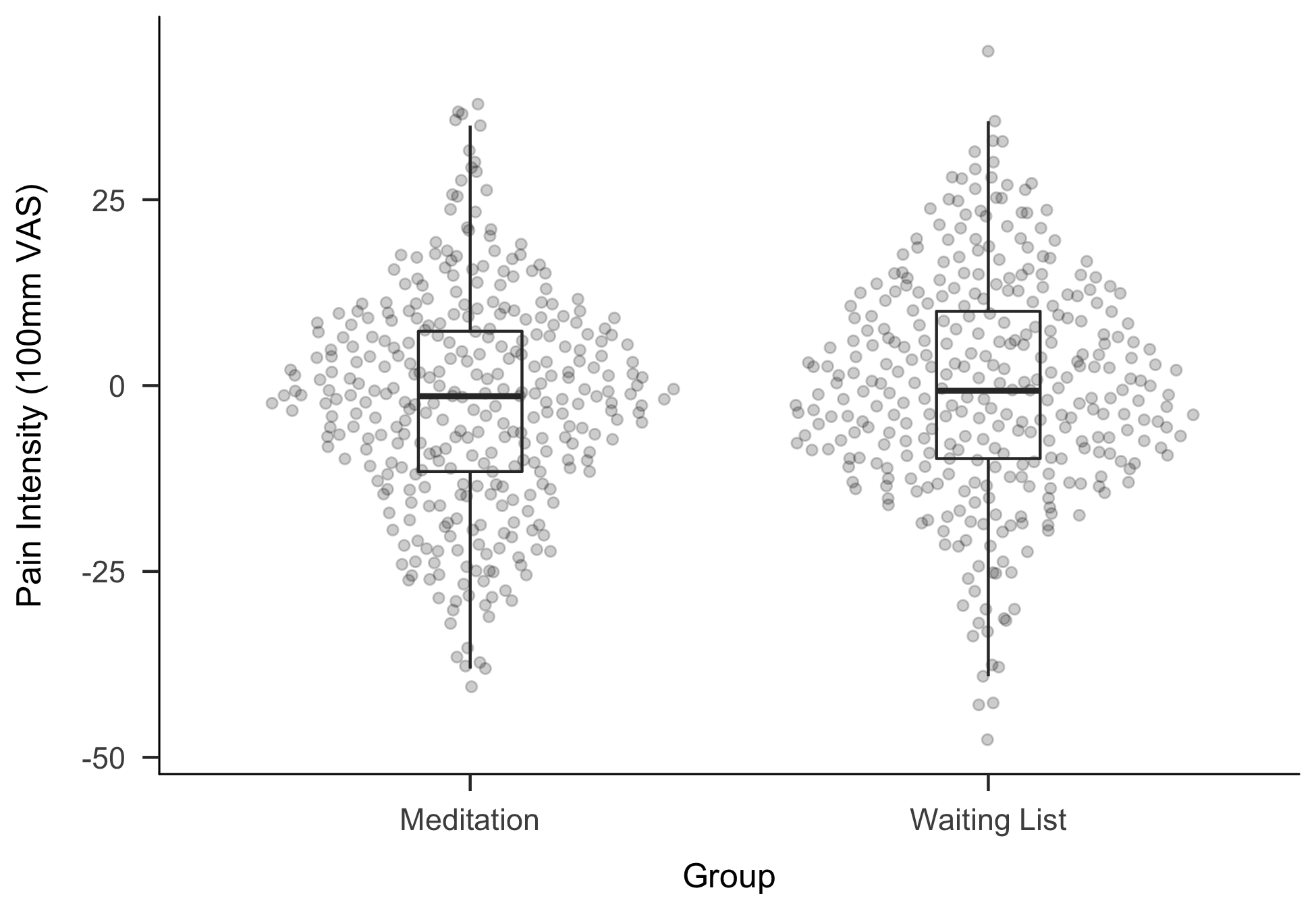
In our paper, titled “Making ‘Null Effects’ Informative: Statistical Techniques and Inferential Frameworks”, we exemplify three different ways to better analyse data when “null effects” occur or are of interest: Equivalence tests, Bayesian estimation and Bayes factors. Along a worked example, we detail how these methods can be used using R, JASP and jamovi. For the example, we simulated data for an imaginary study in which an 8-week meditation intervention is compared to a control group in patients with lower back pain. The study design and research question are not uncommon in many clinical areas, so we hope to provide an accessible and practical introduction.
Everything related to the paper (example data, scripts, manuscript files) are available at a GitHub repository and an OSF project.
The manuscript is currently under review at the Journal of Clinical and Translational Research for a special issue on “null results”, but a pre-print is already available at PsyArXiv.
- This is similar to significant effects: We do not know if we have found a true effect or made a Type I error. ↩
Leave a Reply